Model Overview
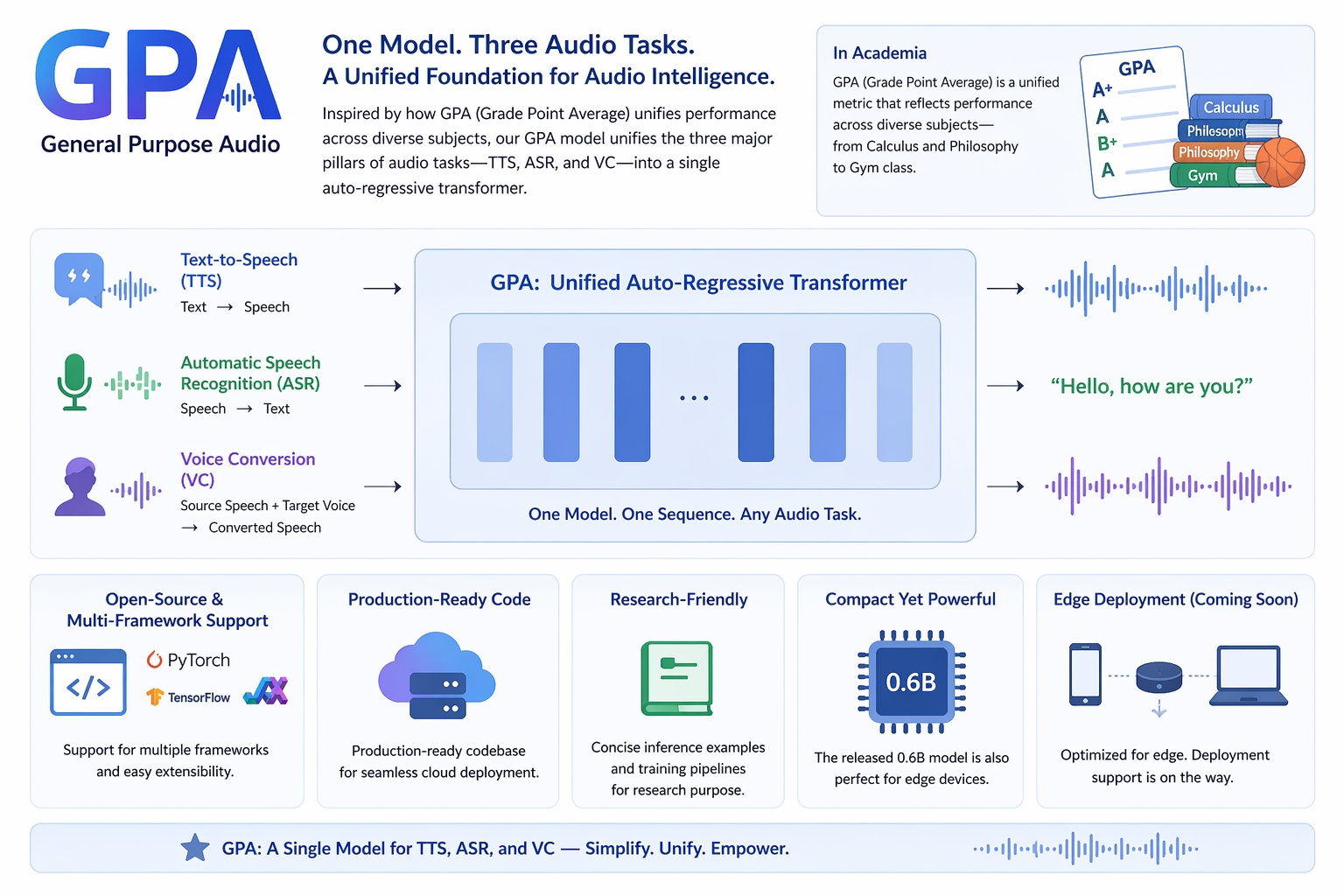
Figure 1. GPA unifies speech understanding and generation in a single autoregressive audio-language model.
Native Train
Fine-tune or continue training GPA-v1.5 with Hugging Face Trainer and the v1.5 training package.
Native Infer
Run direct Hugging Face and PyTorch execution for GPA-v1.5 ASR and TTS behavior baselines.
ONNX Runtime
Use local CLI inference, FastAPI service deployment, browser UI testing, voice registration, and runtime validation.